Uplift modeling is a powerful technique used to determine the incremental impact of a treatment—such as a marketing campaign—on different segments of a population. It helps identify which individuals are more likely to respond to the treatment versus those who would take the desired action regardless, or not at all. But like any modeling approach, uplift modeling comes with its own set of challenges. One of those challenges is multicollinearity.
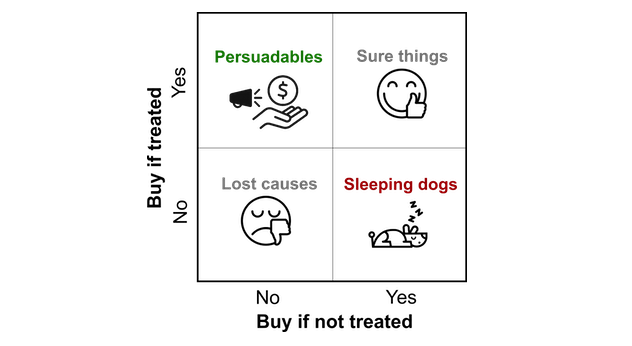
So, is multicollinearity a problem in uplift modeling? The answer is nuanced: sometimes. Let's explore why.
What is Multicollinearity?
Multicollinearity occurs when two or more predictor variables in a model are highly correlated. This means they carry redundant information about the target variable, which can lead to issues when interpreting the model's output. In standard regression models, multicollinearity can inflate the variance of coefficient estimates, making it difficult to discern which predictors truly contribute to the outcome.
Prediction vs. Causal Inference: Where Multicollinearity Matters
When it comes to uplift modeling, we can divide our objectives into two main categories:
- Prediction: Predicting which individuals are most likely to have a differential response to a treatment.
- Causal Inference: Understanding which features are driving the uplift—i.e., identifying the causal drivers of treatment effect.
Multicollinearity isn't much of an issue for prediction in tree-based models like Random Forests or Gradient Boosted Trees. These models are adept at handling correlated features because they select the best feature for each split, making the prediction stable even when features are collinear.
However, multicollinearity becomes a significant problem when you want to make causal inferences about the drivers of uplift. When you aim to understand which features are truly responsible for driving the treatment effect, multicollinearity can obscure the relationships and make the interpretation of feature importance unreliable.
Why Multicollinearity Isn't a Big Deal for Prediction
Tree-based models, which are commonly used in uplift modeling, have a natural robustness to multicollinearity:
- Automatic Feature Selection: During training, tree-based models pick the feature that maximizes information gain or minimizes impurity at each split. When multiple features are correlated, the model will select the one that provides the most utility, effectively sidelining redundant features without affecting predictive performance.
- Shared Attribution: Collinear features might share their contribution to the model’s predictions. While this reduces interpretability, it doesn't necessarily harm the model's predictive power.
If your main goal is accurate targeting—identifying which individuals to treat for the highest uplift—multicollinearity isn’t something you need to worry about much. The model will most likely still provide a strong ranking of who is most likely to respond to treatment.
When Multicollinearity Becomes a Problem: Causal Inference
The story changes if you want to derive insights into the causal mechanisms behind the uplift—i.e., understand which features influence the treatment effect and how. In this case, multicollinearity presents some significant problems:
- Shared Importance: When features are highly correlated, their importance is often shared in the model. This means neither feature may stand out as particularly significant, even if they collectively have a large impact on the treatment effect. This can obscure your ability to identify which feature is truly influential.
- Biased Feature Contributions: Metrics like SHAP (SHapley Additive exPlanations) values or feature importance scores can be misleading. Correlated features will often split their "contribution," leading you to underestimate the true impact of each feature individually.
- Confounding Interactions: In uplift models, interactions between features can play a crucial role in determining treatment effects. Collinear features can create redundant or confounding splits, leading to biased interpretations of which segments of the population are being most influenced by the treatment.
In short, if you’re trying to explain why certain users are more responsive to a treatment, rather than just predicting who they are, multicollinearity can be a real obstacle.
Strategies to Mitigate Multicollinearity in Uplift Modeling
If your goal is causal inference, it’s important to address multicollinearity to ensure that your insights are meaningful and actionable. Here are some strategies to consider:
1. Feature Selection
- Remove Highly Correlated Features: Identify features with high correlation (using techniques like Pearson correlation) and remove redundant features to minimize collinearity. Keeping the most informative features reduces noise.
- Combine Correlated Features: Create a composite feature that captures the information of highly correlated variables. For example, averaging two similar features can reduce redundancy while retaining their informational value.
2. Regularization Techniques
- Lasso (L1) Regularization: This can be useful if you're using linear models within uplift modeling. Lasso helps by shrinking some feature coefficients to zero, effectively selecting a smaller set of non-redundant predictors, which can make interpretation clearer.
3. Advanced Causal Techniques
- Causal Forests: An adaptation of Random Forests, Causal Forests are designed specifically to estimate heterogeneous treatment effects. By focusing on differences between treated and control groups, these models provide more targeted insights into which features are driving the treatment effect.
- Double Machine Learning (DML): This approach combines machine learning with causal inference, helping to control for confounders and reduce bias due to correlated features, resulting in more reliable causal estimates.
4. Interpreting Grouped Features
- Instead of interpreting individual correlated features, group related features into broader categories (e.g., demographic, behavioral). This helps in understanding the collective impact without getting caught in the complexities of individual contributions.
Conclusion: Sometimes, Multicollinearity Is a Problem
Multicollinearity in uplift modeling is a classic "it depends" scenario. For prediction, particularly when using tree-based models, multicollinearity is generally not a problem. The model will still do an excellent job of identifying the users most likely to respond to treatment, making it useful for targeting purposes.
For causal inference, however, multicollinearity can be a significant barrier. It complicates the ability to understand which features are responsible for driving the uplift and can lead to misleading conclusions if not properly addressed.
References: